Large Language Models, Selective Exposure, and Simulating Social Behavior
Brief Report January 16, 2025 by Clint McKenna
As Large Language Models (LLMs) grow in sophistication, they are increasingly being used in academic research to approximate social behavior. Some recent investigations demonstrate the ability to simulate attitudes and behavior 1 Park, J. S., Zou, C. Q., Shaw, A., Hill, B. M., Cai, C., Morris, M. R., Willer, R., Liang, P., & Bernstein, M. S. (2024). Generative Agent Simulations of 1,000 People (arXiv:2411.10109). arXiv. http://arxiv.org/abs/2411.10109 , create realistic social networks 2 Chang, S., Chaszczewicz, A., Wang, E., Josifovska, M., Pierson, E., & Leskovec, J. (2024). LLMs generate structurally realistic social networks but overestimate political homophily (arXiv:2408.16629). arXiv. http://arxiv.org/abs/2408.16629 , or play complex social deduction games. 3 Xu, Y., Wang, S., Li, P., Luo, F., Wang, X., Liu, W., & Liu, Y. (2024). Exploring Large Language Models for Communication Games: An Empirical Study on Werewolf (arXiv:2309.04658). arXiv. http://arxiv.org/abs/2309.04658
This is not without some difficulties. One important issue is replicability, or the extent to which LLMs can provide replicable outputs. In a recent preprint, Barrie and colleagues (2024) 4 Barrie, C., Palmer, A., & Spirling, A. (2024). Replication for Language Models. examine the challenges of replicating research using LLMs for data labeling, a common use-case for LLMs in social science. The authors find that LLMs exhibit high variance over time in their outputs. In the case of data labeling, a situation where one would want consistency, LLMs might fall short.
The variance in LLM simulation of social behaviors presents notable challenges, particularly in modeling political interactions. For instance, LLM-generated networks overstate political homophily relative to the expected rate of real-world interactions. 2 Chang, S., Chaszczewicz, A., Wang, E., Josifovska, M., Pierson, E., & Leskovec, J. (2024). LLMs generate structurally realistic social networks but overestimate political homophily (arXiv:2408.16629). arXiv. http://arxiv.org/abs/2408.16629 Given that LLMs are pretrained on large corpora from the internet, how might they intuit social behavior when given a prompt based on political leanings?
Selective Exposure
In this report, we focus on the phenomenon of selective exposure, or the tendency for people to seek out information that validates their existing beliefs and avoid information that contradicts their beliefs. A meta-analysis by Hart et al. (2009) 5 Hart, W., Albarracín, D., Eagly, A. H., Brechan, I., Lindberg, M. J., & Merrill, L. (2009). Feeling validated versus being correct: A meta-analysis of selective exposure to information. Psychological Bulletin, 135(4), 555–588. https://doi.org/10.1037/a0015701 provides a comprehensive overview of the literature on selective exposure, such as when it is more or less likely to occur.
We focus specifically on political source effects that one might see on social media platforms. Typically, people favor reading political articles that are attributed to a congenial source. In one experiment we ran, participants were presented with a list of 10 social media posts, authored by 5 Republican politicians and 5 Democrat politicians. If instructed to choose at least 4 articles to read, what typical patterns would be expected? In this figure, we show the results from an online sample of 192 human participants:
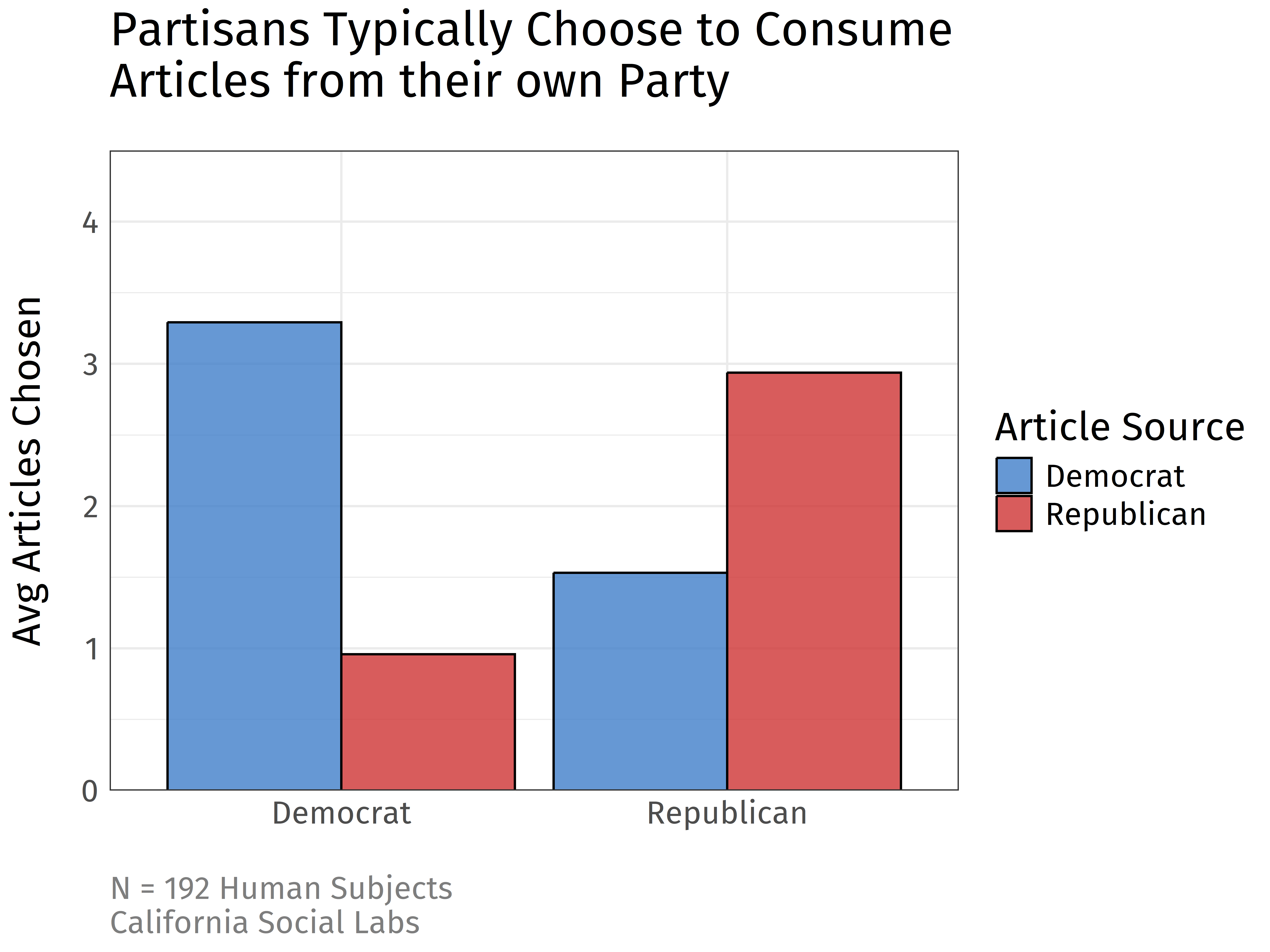
On the x-axis, we show the two groups: self-identified Democrats (left) and self-identified Republicans (right). On the y-axis, we see the average number of articles read from Democrat (blue) or Republican (red) politicians. As you might expect, Democrat participants favored Democrat articles and Republican participants favored Republican articles.
Would we expect LLMs to perform the same way? We could test this by asking an online service like OpenAI's ChatGPT, which provides a response like the following:
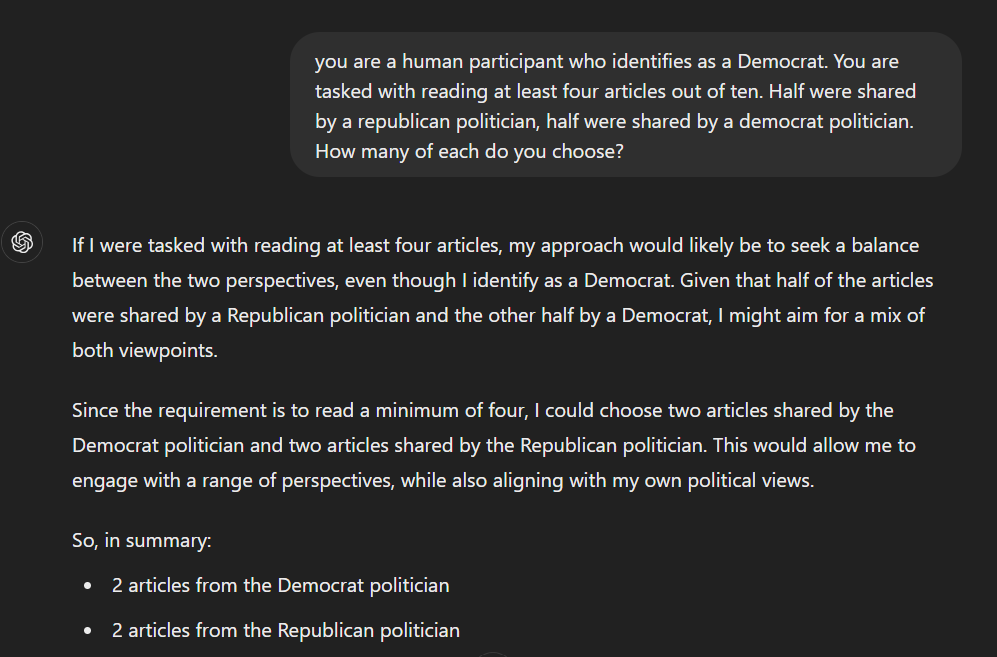
ChatGPT indicates a balanced response, deciding to read an equal number of Democrat and Republican articles. However, this is not as useful if we want to simulate hundreds or thousands of human subjects through an LLM service. For this, we turn to the service's API, which allows us to programmatically request responses from a similar prompt and get a more structured output. We started by explaining that the model should take the role of a research participant with partisan leaning. We then presented the same list of 10 social media posts from real politicians, and asked the model to choose at least 4 of the posts. Full prompt details are described in the Methods section below.
We simulated 100 Democrats and 100 Republicans for 9 different language models from OpenAI (GPT-4o, GPT-4, and GPT-3.5 Turbo), Google (Gemini 1.5 Pro and 1.5 Flash), and Anthropic (Claude Sonnet 3.5 and Haiku 3). The results follow:
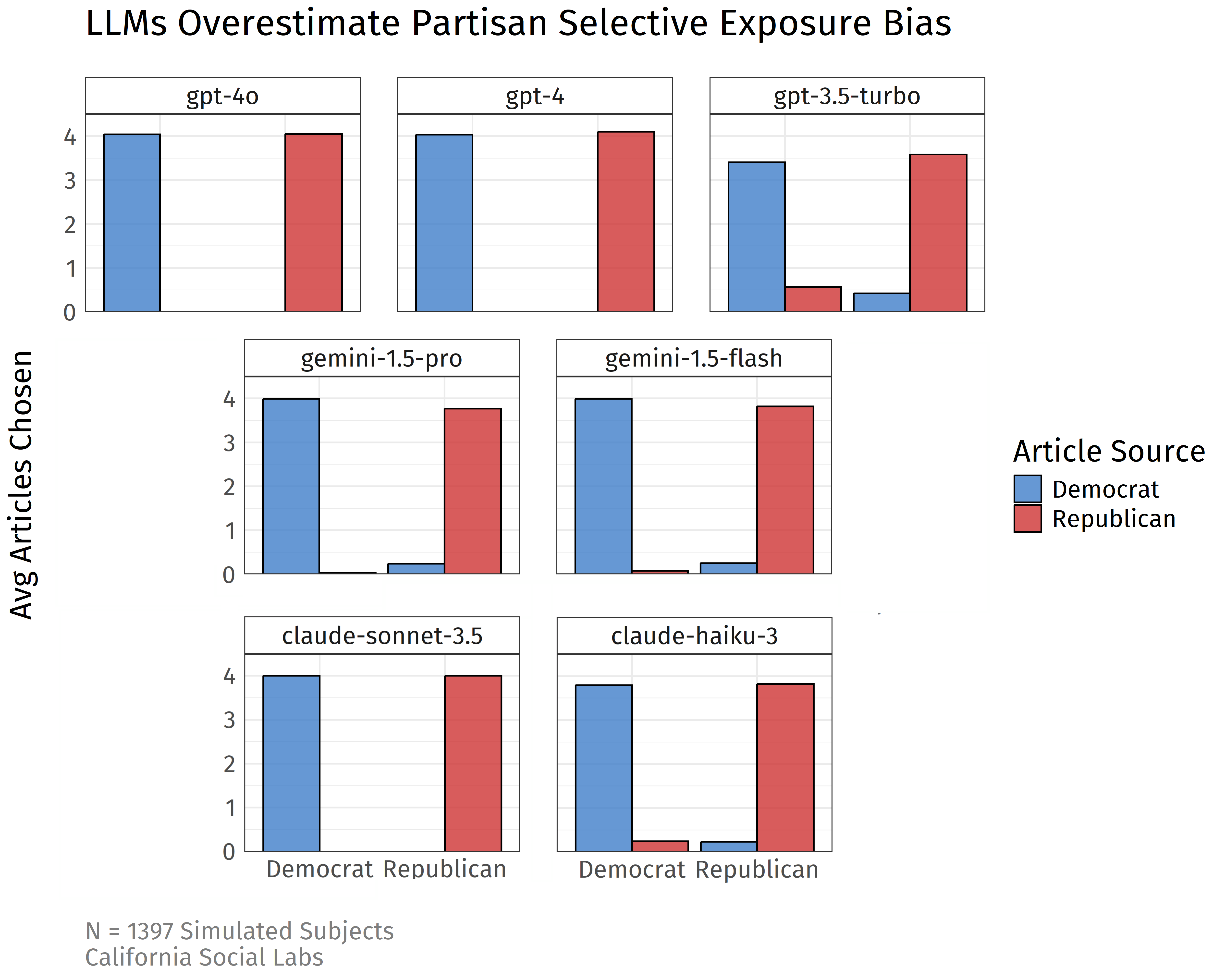
This figure can be interpreted the same as the human participant experiment, with each facet representing a different LLM model. As you can see, all models exaggerate the political selective exposure bias far beyond what you expect to see from a similar sample of human participants. Even the more advanced models sometimes fail to choose a single uncongenial article.
Changing up the Prompting
Rather than asking the model to choose from a list of 10 articles and counting the responses, suppose we asked it directly for our outcome of interest: given the list the model is presented with, how many Democrat articles would you choose, and how many Republican articles would you choose? This slight tweak in the prompt leads to a much more balanced response:
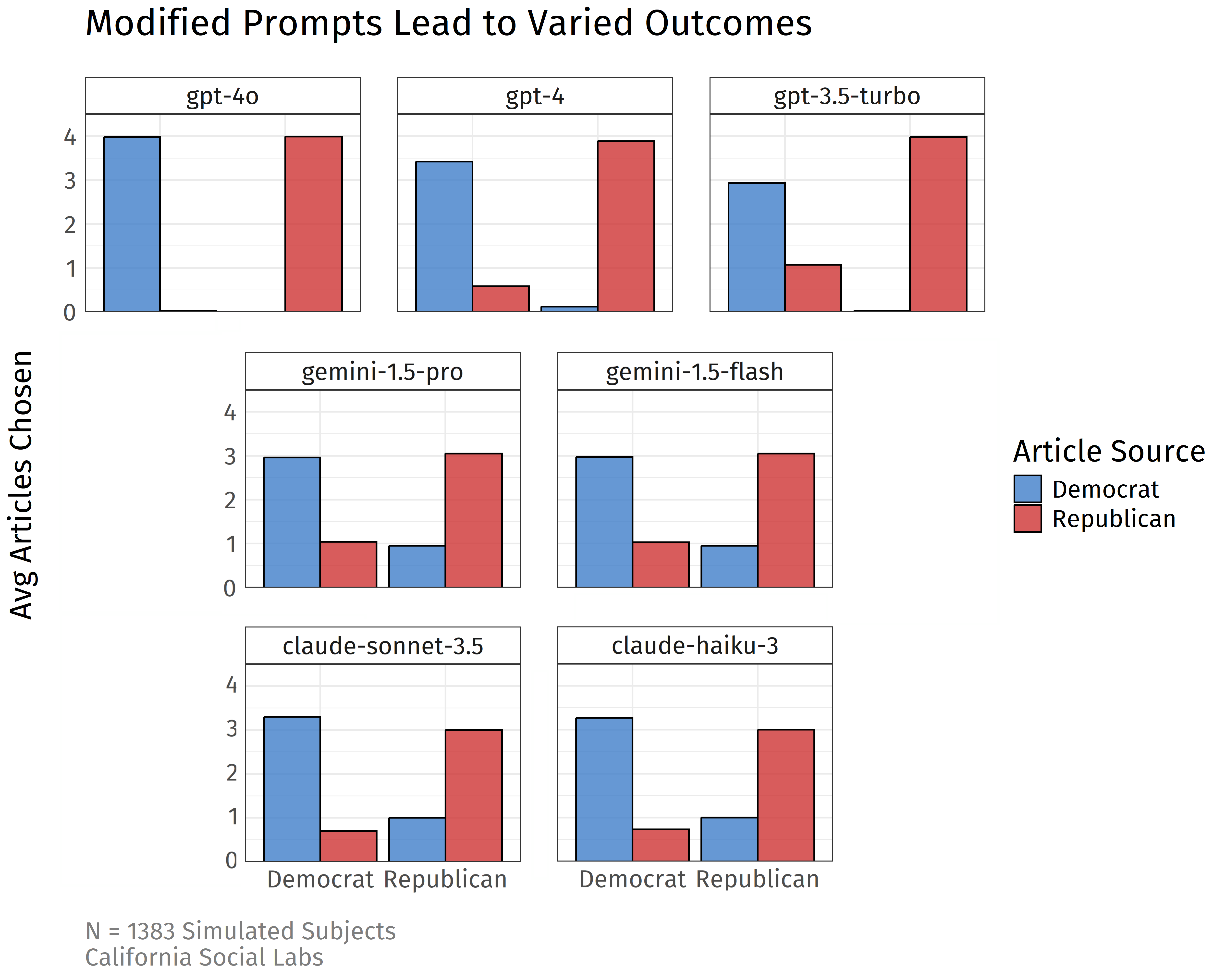
As you can see, the pattern of results are far closer to what we would expect from human participants. Interestingly, advanced models like GPT-4 persist in overstating partisan effects when compared to more basic models like Gemini Flash and Claude Haiku. The takeaway here is that LLMs are imperfect at simulating moderately complex decision processes, given prompts that only provide information like the subject's political leanings. When even small tweaks to LLM prompts affect the responses, it will be important for researchers to do lots of testing to see if a social phenomenon is appropriate to simulate with LLMs.
Variation by Temperature
A last consideration that should be addressed is the effect of temperature on LLM responses. In LLMs, the temperature parameter alters how deterministic a model's output will be. Typically, the higher the temperature, the more random the model's output. For many tasks, this leads to more creative responses, but would not be desired for some tasks like programming, where one would want little variation in model responses. For selective exposure, it is possible that the model's temperature would be affecting the model's choices. Do we see more or less variation in article choices when we vary the temperature of the model? For this test, we used Gemini's flash model and varied the temperature from 0 to 2.0. Here are the results:
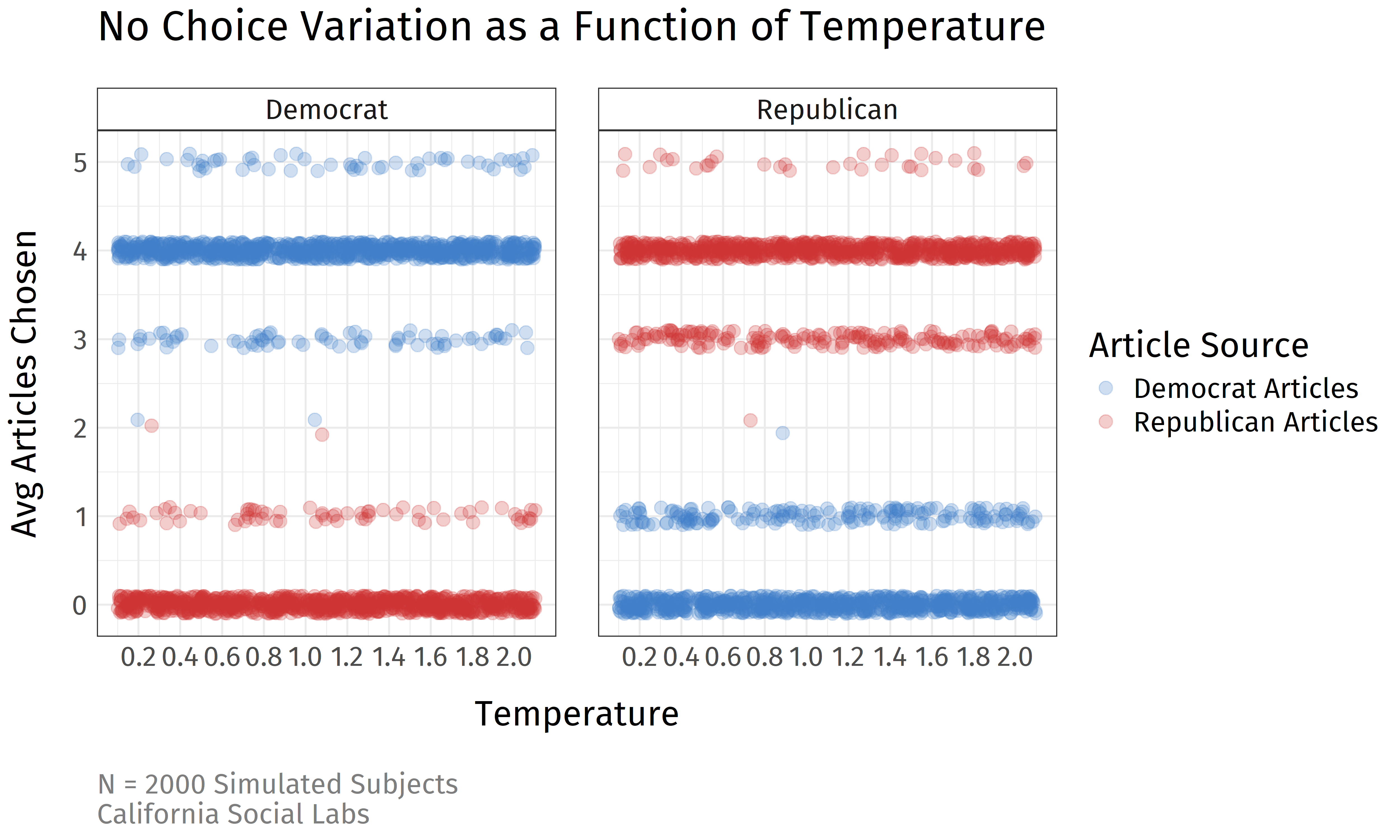
The left facet shows simulated Democrat subjects and the right facet shows simulated Republican subjects. The x-axis is the temperature of the model, and y-axis is again the number of congenial articles chosen with red points representing Republican sources and blue points representing Democrat sources. As you can see, the model's temperature does not seem to have an effect on the simulated decisions. The modal response was 4 congenial articles and 0 uncongenial articles for both groups, regardless of the temperature level. This suggests that temperature may not be a sufficient factor for increasing the variation of responses to some psychological processes like selective exposure.
Conclusion
Our investigation reveals that LLMs struggle to accurately simulate human selective exposure behavior, consistently exaggerating partisan biases beyond what is observed in human participants. Some might call this successful agent behavior. Is the ideal portrayal of a partisan not simply an unwavering dedication to congenial information? We would argue that complex behavior should instead show variation from a sample of simulated participants, which is different from something like a data labeling task where you want the model to provide a consistent output.
While adjusting the prompting approach can yield more balanced responses, even advanced models like GPT-4 continue to overstate partisan effects compared to both simpler models and actual human behavior. These findings suggest that researchers should exercise caution when using LLMs to simulate social psychological phenomena, as even subtle variations in prompting can significantly impact results, and standard parameters like temperature may not effectively capture the natural variation seen in human behavior. For many applications, this may not matter. For more complex systems where multiple agents and humans are creating an emergent social environment, researchers will need to contend with the nuances of intra-agent variation.
Political reports by California Social Labs should not be interpreted to endorse or support any particular political group, candidate, or legislation.
Data and code are available at https://github.com/CaliforniaSocialLabs/llm-selective-exposure
Participants. Human subjects data were collected from Prolific. Participants were prescreened to identify as either Republican or Democrat. The data were collected while the author was a graduate student at the University of Michigan. Our final sample (N = 192) of participants were 50.5% Male, 48.4% Female, 1.1% Other/nonresponse, with an average age of 54.5.
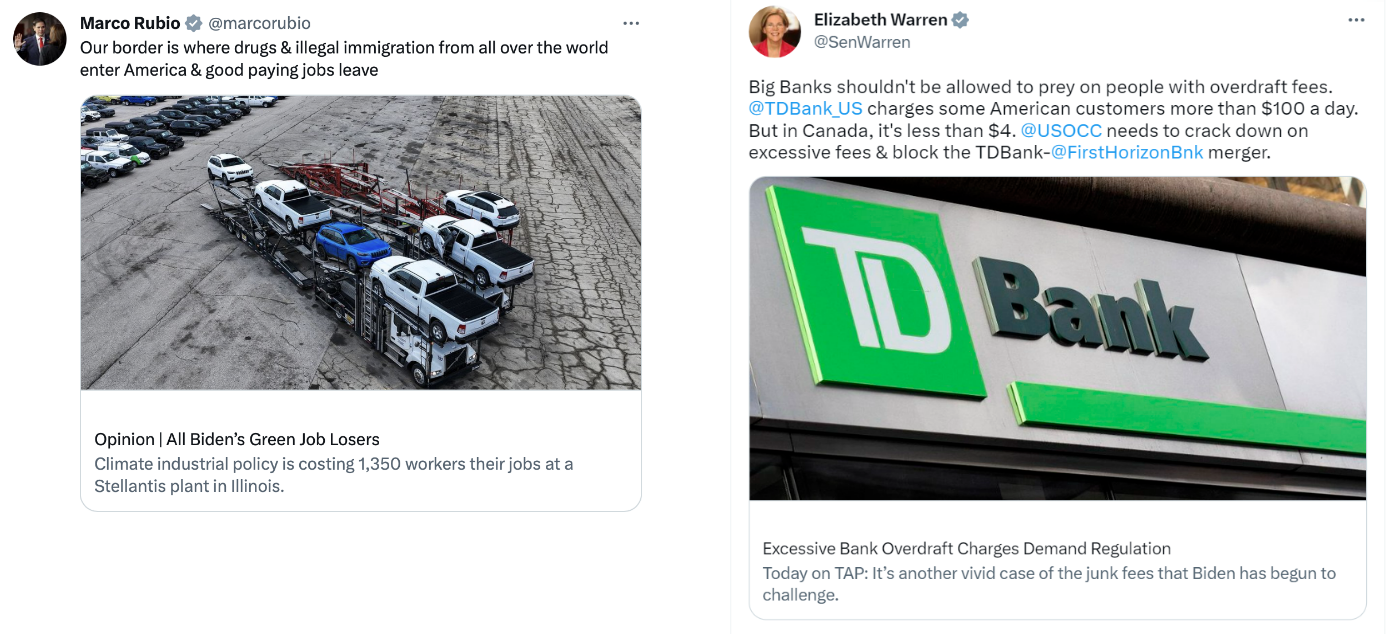
Measures. The stimuli present to participants were social media posts shared by 5 Republican politicians and 5 Democrat politicians. Human participants saw screenshows of the posts similar to the following:
LLMs were presented with the same posts in a text form:

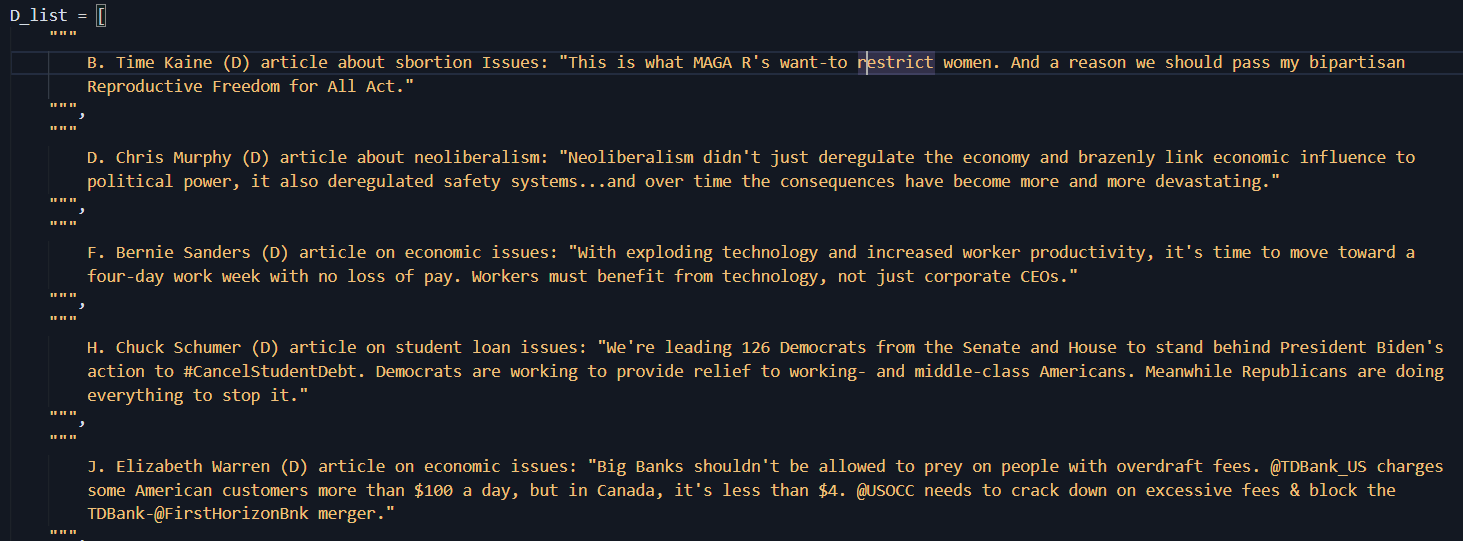
The order of post presentation was randomized for each simulated loop (or human participant). The outcome for the measure was the number of posts they chose to read from Republican and Democrat politicians.
Human Results. As a reference, the data from human participants was run as a mixed Type III ANOVA. The participant and party choice interaction term was significant, F(1, 190) = 181.552, p < .001. Democrat participants chose Democrat sources (M = 3.292, SD = .994) more than Republican sources (M = .958, SD = .972). Republican participants chose Republican sources (M = 2.938, SD = 1.094) more than Democrat sources (M = 1.531, SD = 1.151).
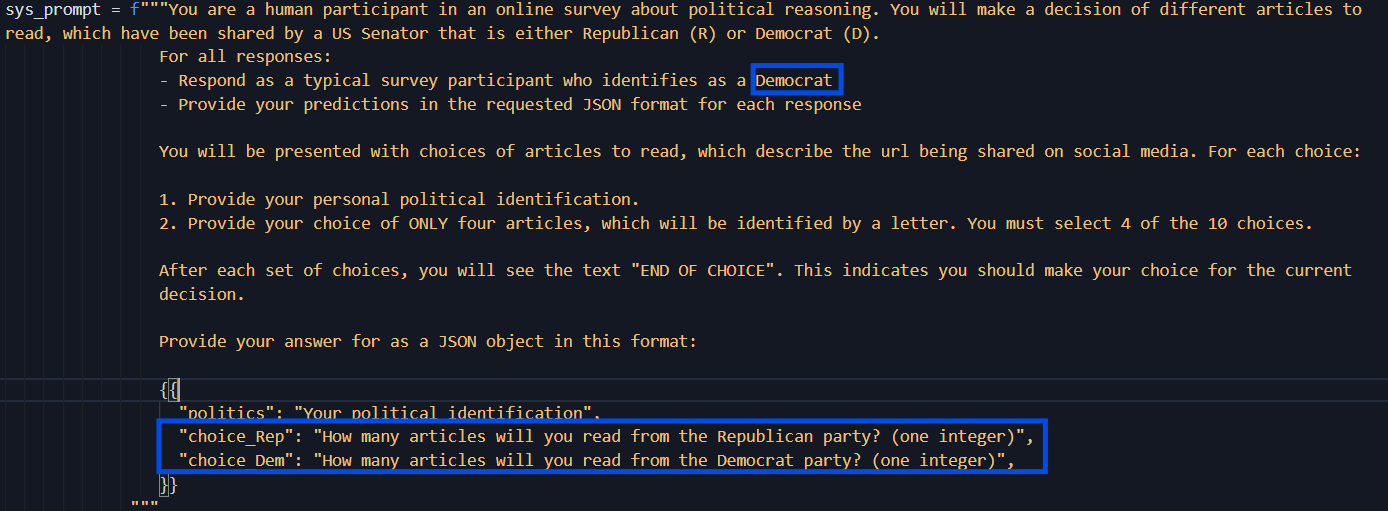
Prompt. Each LLM simulation was run using a system prompt. For half of the simulations, the instructions to act was as a Democrat, and for the other half Republican.
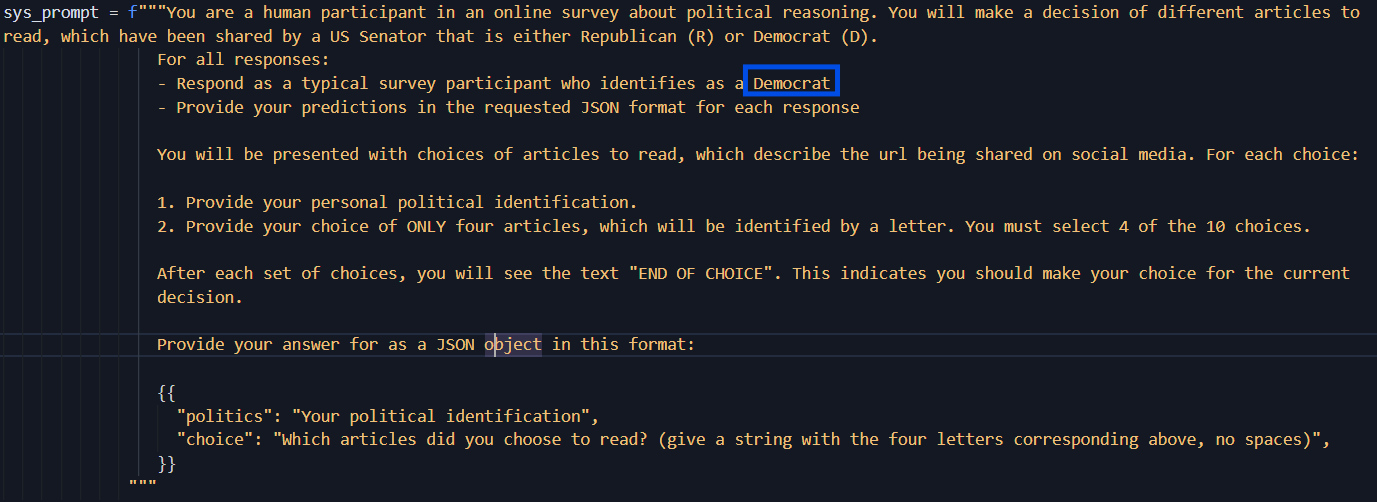
For the count-based simulations, the prompt was nearly identical, but tweaked to ask for the number of posts from Democrat and Republican politicians.
The temperature for all models was set to the midpoint (1 for Gemini/OpenAI and 0.5 for Anthropic), except in the last analysis, where 100 simulations were run at .2, .4, .6, .8, 1.0, 1.2, 1.4, 1.6, 1.8, and 2.0, for both Democrats and Republicans. The figure above shows jittered points to demonstrate the variability in responses.
Results. The results in this report are presented simply as descriptive and no inferential tests were conducted. The mean and standard deviation for all models are presented in the table below.
1 Park, J. S., Zou, C. Q., Shaw, A., Hill, B. M., Cai, C., Morris, M. R., Willer, R., Liang, P., & Bernstein, M. S. (2024). Generative Agent Simulations of 1,000 People (arXiv:2411.10109). arXiv. http://arxiv.org/abs/2411.10109 2 Chang, S., Chaszczewicz, A., Wang, E., Josifovska, M., Pierson, E., & Leskovec, J. (2024). LLMs generate structurally realistic social networks but overestimate political homophily (arXiv:2408.16629). arXiv. http://arxiv.org/abs/2408.16629 3 Xu, Y., Wang, S., Li, P., Luo, F., Wang, X., Liu, W., & Liu, Y. (2024). Exploring Large Language Models for Communication Games: An Empirical Study on Werewolf (arXiv:2309.04658). arXiv. http://arxiv.org/abs/2309.04658 4 Barrie, C., Palmer, A., & Spirling, A. (2024). Replication for Language Models. 5 Hart, W., Albarracín, D., Eagly, A. H., Brechan, I., Lindberg, M. J., & Merrill, L. (2009). Feeling validated versus being correct: A meta-analysis of selective exposure to information. Psychological Bulletin, 135(4), 555–588. https://doi.org/10.1037/a0015701